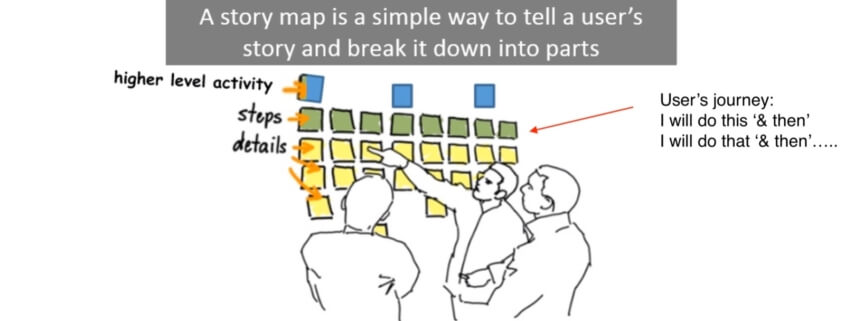
What Are Spikes And How To Estimate Them?
Spikes are special stories or work items and they are handled slightly differently. When we work on a project, there are different kinds of work items. Some are about modifying existing functionalities and some are about creating new ones. There are also work items which help make the project better, such as enhancing its performance, faster speed, better look and feel, etc. While creating new functionalities is about understanding the requirements, making the project better or smarter might need some research to be done to create the right requirements. This latter work is what spikes are all about. Let us understand spikes by visiting a few examples. Story 1: As a baker, I like to bake pumpkin bread so that I can reward my kids for the chores they do. Story 2: As a baker, I would like to bake pumpkin bread with a different flour than I am used to, so that I can surprise my kids with a delightful new flavor. I usually bake using all-purpose flour (Story 1). But what happens if I want to use a different flour (Story 2)? For example, for Story 2, I could use semolina flour, or whole wheat flour, or cake flour, etc. Now, in order for me to understand relatively how complex it is to bake with a new primary ingredient (type of flour in this case), I may have to do some research. So looking at the examples above, the effort needed in Story 2 may not be estimable unless I do some research. This calls for a spike*. An example is given below. Spike: Research what is needed in terms of equipment, precautions, handling the new ingredient in certain specific ways, preparation, instructions etc., to bake effectively using flours that is different from the usual whole purpose flour. Bringing this back to software development, similar research backlog items are called Spikes. Spikes are therefore created for the team to gain more information before an actual story related to a functionality can be estimated. They are meant to bring clarification to our functionality. Spikes are timeboxed, meaning that the team in agreement with the Product Owner or with their support, decides to invest, say N hours of research and bring out information that can help estimate the work in implementing the functionality. This is similar to the metaphor of a rock climber hammering a spike into the rock**. Although the climber may not be climbing at that moment, the spikes they are working on would still enable them to move forward with their work. After these N hours or so of work that is done in a sprint, the team pauses and shares the research with the Product Owner. At that time, the Product Owner decides if they have enough information to move forward with the project or they may request for additional spike items that are timeboxed to another chunk of hours. This is how spikes are timeboxed. But the bigger question is, how do we include a timeboxed spike as part of our velocity (the amount of work delivered in a sprint expressed in terms of total number of story points)? Here’s one way it can be done. As an agile team continues to work for a few iterations, they realize their story points have certain (hour/time) ranges. For example, a 1-point story could range from 2 to 8 hours. The best case 1-point story may take around 2 hours, and the worst case story might take around 8 hours (These are hypothetical numbers and can be different for different teams). In the same way, the 2-point stories could range between 4 to 13 hours (again, hypothetically speaking). Once this relationship is established between story points and hours for a team, it is easier to convert timeboxed spikes to story points. Say, a team wants to now timebox a spike of N=20 hours, they can map into a relevant story point (for example it could be their 3-point story range). This is a good, organic way to provide story point estimates for your spikes. This exercise of story point vs. hours is usually facilitated by the Scrum Master working with the team after the team has completed a few sprints. This relationship between story points and hours also helps the team improve its story point estimation accuracy. But what about a team that still hasn’t figured out their story-point-to-hours relationship? Either the team isn’t estimating consistently, or isn’t estimating as a team, or they don’t understand the story point estimation. Or it could even be that they have just started working together as a new team. For such teams, it is recommended that they start with some kind of a range. But they should be open to taking feedback from their actual work items as they move on from sprint to sprint. It is not recommended to fix a number of story points to a fixed number of hours as is prescribed by some scaling frameworks. What are your thoughts? How do you normally estimate your spike backlog items? *coined by Kent Beck, was originally defined as “a very simple program to explore potential solutions” ** Paul from www.agilelogic.com commented that the etymology of the term “comes from an analogy to rock climbing. When climbing, we might stop to drive a spike into the rock face. Driving the spike is not actual climbing — it does not move us closer to the top — but rather it enables future climbing”. Palmer, agreed saying that it’s “where you put a spike in the mountain on your way up. If the spike sticks, then it’s ok to go that way”. Amitabh (Amit) Sinha is a servant leader entrepreneur, visionary, mentor, trainer and coach. Amit is highly passionate about Agile, its principles, values, and the human side. Amit is a people champion and strives to bring out the best in his teams. Amit leverages his expertise in Agile, Scrum, Kanban and people skills to increase team effectiveness and